Hi, I’m Oliver
Data
I am an aspiring Data Scientist who is interested in gaining a better understanding of the environment(s)
around us. I enjoy spending time thinking (and coding) outside of the box.
Scientist.
Problem Solver.
Projects
Climate Dynamics
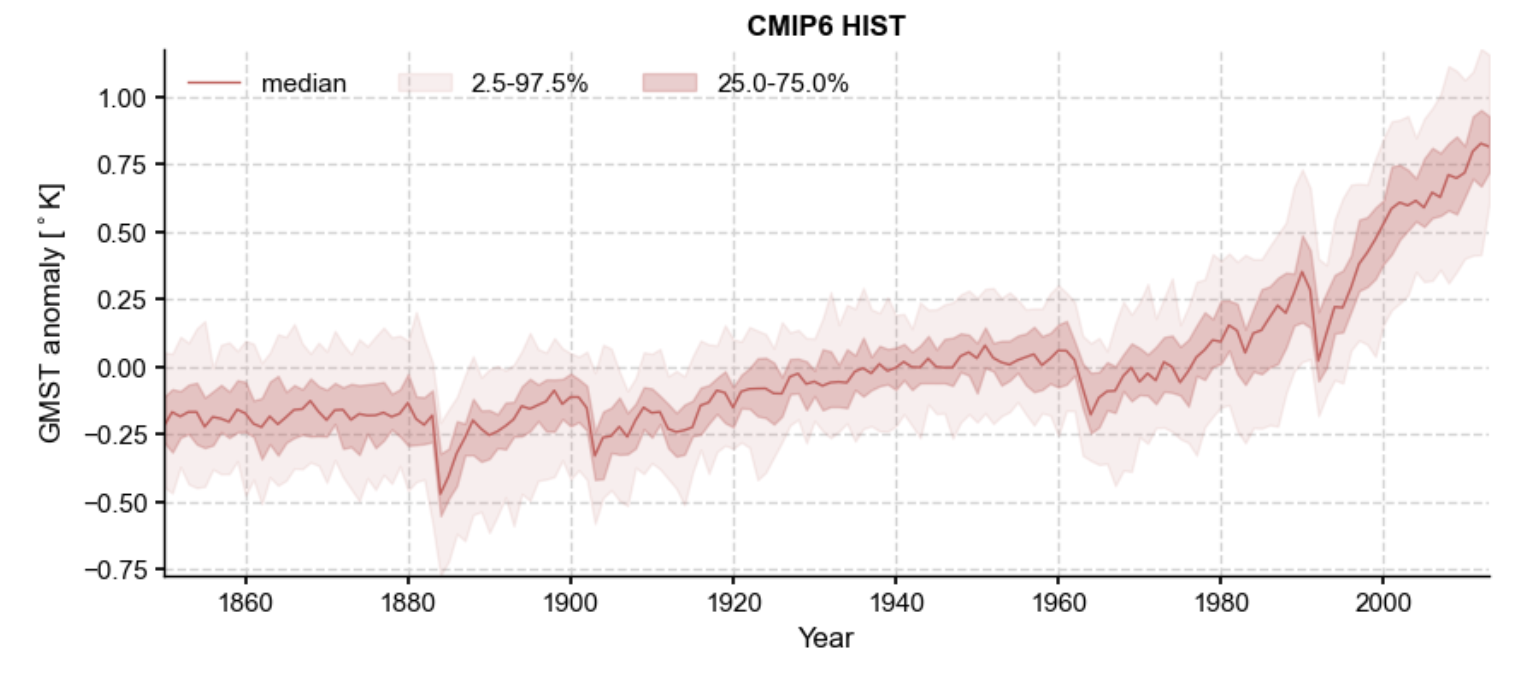 Climate change is undoubtedly one of the leading existential threats we face today. Combatting this threat and improving our understanding of the environments around us, thousands of scientists actively study Earth’s climate to inspire solutions. Beginning in the summer of 2023, I interned as a research assistant at USC’s Climate Dynamics Lab. My primary task was to produce a model that analyzes the net warming trends (heating anomalies) in Earth's atmosphere from the last few thousand years through the 22nd century. To read more about my research and view the repository, click here.
Climate change is undoubtedly one of the leading existential threats we face today. Combatting this threat and improving our understanding of the environments around us, thousands of scientists actively study Earth’s climate to inspire solutions. Beginning in the summer of 2023, I interned as a research assistant at USC’s Climate Dynamics Lab. My primary task was to produce a model that analyzes the net warming trends (heating anomalies) in Earth's atmosphere from the last few thousand years through the 22nd century. To read more about my research and view the repository, click here.
Climate change is undoubtedly one of the leading existential threats we face today. Combatting this threat and improving our understanding of the environments around us, thousands of scientists actively study Earth’s climate to inspire solutions. Beginning in the summer of 2023, I interned as a research assistant at USC’s Climate Dynamics Lab. My primary task was to produce a model that analyzes the net warming trends (heating anomalies) in Earth's atmosphere from the last few thousand years through the 22nd century. To read more about my research and view the repository, click here.
CNN-LSTM Deep Learning
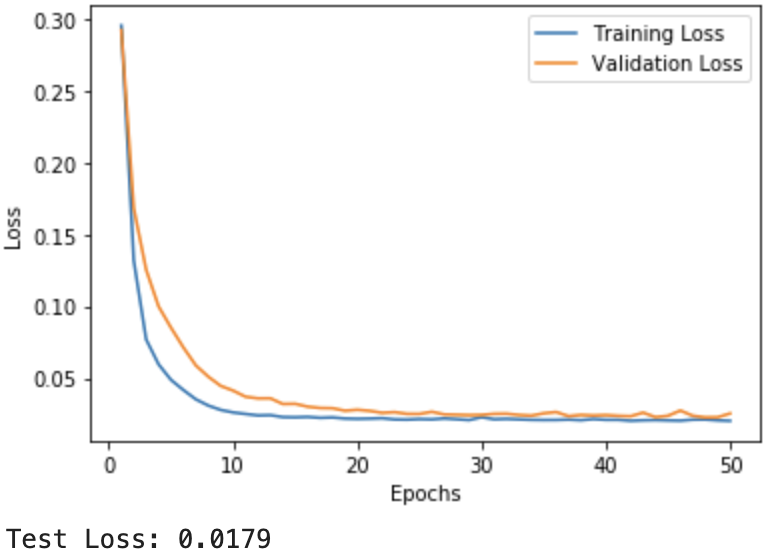 In 2015, the U.N. introduced 17 sustainable development goals, or SDGs, to strategically focus on healthier economic development towards 2030. One of the SDGs focuses on reducing greenhouse gas emissions and being inspired by this, my peers and I wanted to see if we could predict air quality patterns to gain a better understanding of how to minimize them. Starting from scratch, I designed a deep-learning model to predict the future presence of particulate matter in our atmosphere. I calculated all of the tensor and convolution dimensions firstly by hand and then proceeded to implement it using PyTorch. The model was trained off of time series data, to learn more and view the code, click here.
In 2015, the U.N. introduced 17 sustainable development goals, or SDGs, to strategically focus on healthier economic development towards 2030. One of the SDGs focuses on reducing greenhouse gas emissions and being inspired by this, my peers and I wanted to see if we could predict air quality patterns to gain a better understanding of how to minimize them. Starting from scratch, I designed a deep-learning model to predict the future presence of particulate matter in our atmosphere. I calculated all of the tensor and convolution dimensions firstly by hand and then proceeded to implement it using PyTorch. The model was trained off of time series data, to learn more and view the code, click here.
In 2015, the U.N. introduced 17 sustainable development goals, or SDGs, to strategically focus on healthier economic development towards 2030. One of the SDGs focuses on reducing greenhouse gas emissions and being inspired by this, my peers and I wanted to see if we could predict air quality patterns to gain a better understanding of how to minimize them. Starting from scratch, I designed a deep-learning model to predict the future presence of particulate matter in our atmosphere. I calculated all of the tensor and convolution dimensions firstly by hand and then proceeded to implement it using PyTorch. The model was trained off of time series data, to learn more and view the code, click here.
MusicaHub (GeoListen)
MusicaHub is a full-stack web development project that allows users to stay up to date on the "global" listening experience. Powered by Spotify's REST API, the platform is constantly updated on any recent changes to the playlist(s) located in Spotify. The songs page features a dynamic loading UI. The platform utilizes SQL to manage user states, metadata, and so on for a heightened experience. Through the different user states such as admin, regular, and guest, the project effectively provides CRUD functionality. For more info, click here.
Labor Force Sentiment Analysis
Currently: generating a text corpus. This proved to be harder than expected- depleted APIs, paywalls, HTTP request limits, etc.
Next Steps: Planning to accquire more article data, but for now using NYTimes metadata and articles, I am going to hypertune a pre-trained BERTL model using HuggingFace. Afterwards, I predict the sentiment analysis from 2000 to the present, set a base-line (zeroing out), and record the anomalies. After that is the fun part- compare and constrast with economic metrics such as underemployment rate, interest rates, and so on.
Next Steps: Planning to accquire more article data, but for now using NYTimes metadata and articles, I am going to hypertune a pre-trained BERTL model using HuggingFace. Afterwards, I predict the sentiment analysis from 2000 to the present, set a base-line (zeroing out), and record the anomalies. After that is the fun part- compare and constrast with economic metrics such as underemployment rate, interest rates, and so on.

I am a recent graduate from the University of Southern California (Fight On!) where I hold a dual degree in Data Science & International Relations and the Global Economy. I am currently seeking career opportunities in data science and adjunct fields where I look forward to working hard, and improving upon my technical abilities.
In addition to my interest in all things computer, I am a genuinely curious person. I enjoy learning about various subjects from philosophy and history (currently early renaissance) to mathematics and macro economics & finance. In my free time, I enjoy working out, reading, learning guitar and watching the Chicago Cubs beat the Chicago White Sox.